
BACKGROUNDAt Motif Technologies, we're building a versatile AI platform designed to handle a wide range of tasks. This platform integrates both external APIs, like those from OpenAI, and our own internal servers for various model inferences. For chat-based applications, we use the vLLM library to deploy a mix of in-house models, such as Motif-2.6B, and leading open-source models. Furthermore, we're also preparing our own Hosted Inference API service, where we aim to provide a simple interface to the best open source models.And because we're in a world where newer and better open source models come out every once in a while, our team is not hesitant to try them out and test them to see if they better suit our needs. This year alone, we have deployed and tested several different prominent open source models, including Meta's Llama-3-70B, Google's Gemma-3-27B, and OpenAI's GPT-OSS-120B. Recently we came across Alibaba's Qwen-3-235B-A22B, and the deployment of this model was little different due to the massive size of the model. Therefore, we had to split the model into multiple nodes utilizing vLLM's multi-node, multi-GPU inference feature.Our environment is somewhat unique, as we're running on AMD's MI250 GPUs. This post aims to assist those looking to set up distributed inference on such devices.
The setup for this blog post was tested under the following environment:
- ROCm version: 6.3.0.60300-39~22.04
- Docker version: 28.3.3, build 980b856
- Image: rocm/vllm:rocm6.3.1_instinct_vllm0.8.3_20250410
vLLM INFERENCEBefore going to the multi-node setup, let's see how to run a single node vLLM instance using docker.In the vLLM official documentation, there is a section on manually building docker images for AMD GPUs. Luckily, AMD maintains a separate repository just for vLLM images. Look through the repository to find the one that matches your environment.
Before trying out any vllm-rocm images, check if your host machine(operating system and ROCm version) is compatible with your target vLLM image. Details can be found here. One way to check your ROCm version is to run
In order to run the apt show rocm-libs -a.vllm-rocm image, special parameters should be provided to the docker run command.docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
rocm/vllm:rocm6.3.1_instinct_vllm0.8.3_20250410 \
sleep infinityA simple explanation on what the parameters are for:
group-add, security-opt: graphic driver related authorizationdevice(kfd): kernel fusion driver related authorizationdevice(dri): direct rendering infrastructure related authorizationipc: for shared memory used by the vLLM process
/dev/kfd should be included in Deployment's container volume specification).MULTI-NODE DISTRIBUTED INFERENCE (WITH RAY)As long as the model can be fitted into a single node, the image above should be able to cover up all usecases. Things become trickier when the model size is too big for a single node GPU. vLLM has a dedicated page on parallelism and scaling, and the key concept here is You can see
2. the IP address of your node (
3. network interface name(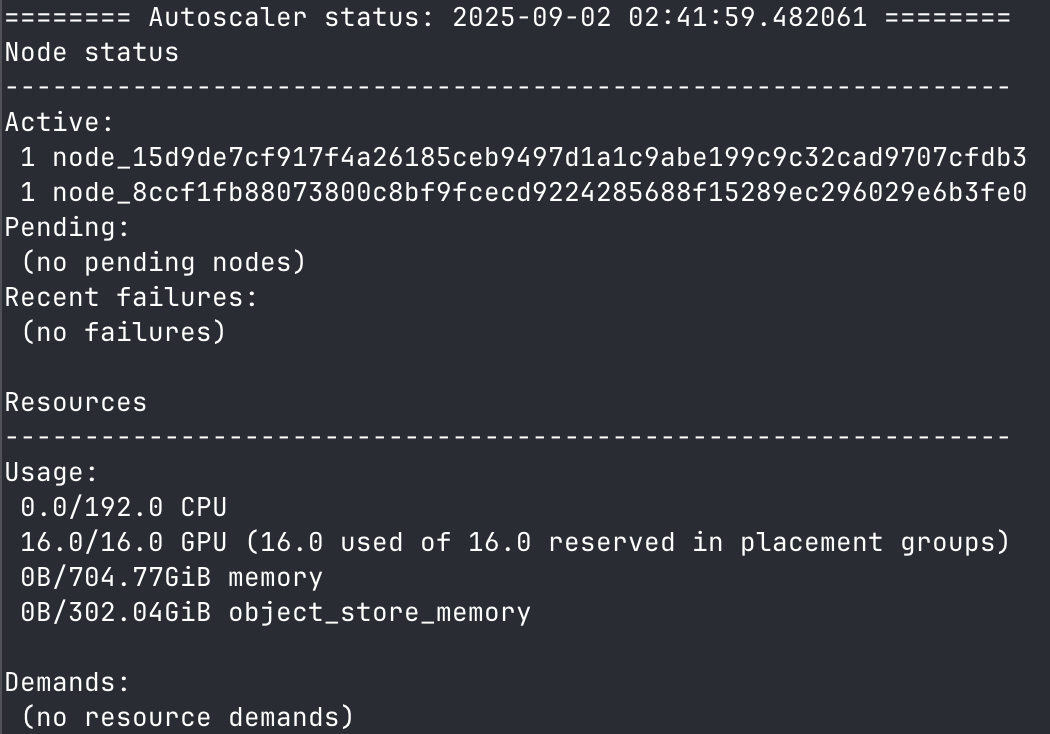 Example of a 2 node Ray cluster (using If you only see 1 node running in your cluster even after setting up your worker node ray process, it's most likely that the worker node ray process failed to connect to the head node. Confirm you have the right head node IP address. Confirm you have the right number of nodes on your cluster before moving on.SERVE MODEL USING vLLM
Example of a 2 node Ray cluster (using If you only see 1 node running in your cluster even after setting up your worker node ray process, it's most likely that the worker node ray process failed to connect to the head node. Confirm you have the right head node IP address. Confirm you have the right number of nodes on your cluster before moving on.SERVE MODEL USING vLLM
Ray. Ray is a distributed compute framework that allows you to connect processes and group them into a cluster.Therefore, if we have a model that needs 2 nodes of GPUs we need a way to group the nodes into a single cluster. This is where Ray comes in. Assuming we're setting up a 2-node(1 head, 1 worker) distributed inference(though this can be done in any N-node setting), let's walkthrough step by step of how we can setup distributed inference. We have our nodes setup in our kubernetes cluster, but you can do this without a k8s cluster as well.SPIN UP vLLM CONTAINERS (for Distributed Inference)There are more kubernetes-native way to manage a ray cluster(e.g. KubeRay), but we would be setting them up directly inside the node themselves. Before doing anything else, we need to set up vLLM on each of our nodes, and this would be done through docker. Here is the script.#1 Set container name, IP address, and network interface name
CONTAINER_NAME=$1
IP=$2
INTERFACE=$3
echo "IP address of $INTERFACE is $IP"
#2 Run docker
docker run -it --name $CONTAINER_NAME -d \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-e GLOO_SOCKET_IFNAME=$INTERFACE \
-e VLLM_HOST_IP=$IP \
rocm/vllm:rocm6.3.1_instinct_vllm0.8.3_20250410 \ # vllm-rocm image
sleep infinitythe docker run command is almost identical to the single node command I mentioned above. This script takes 3 extra arguments, of which 2 of them are necessary and important for the distributed inference.1. name for you docker container(e.g. head-node, worker-node)2. the IP address of your node (
$2)3. network interface name(
$3)If the environment is kubernetes, the IP address can be retrieved by running kubectl get nodes -o wide, under INTERNAL-IP. For the network interface name, use the network interface utility (e.g. ifconfig). Since Ray uses the primary network interface by default, select your primary network interface(e.g. eno, the one that reaches the internet).Although specialized standards like InfiniBand (IB) excel at interconnecting servers, Ethernet communication also works fine. We'll talk more about how IB works in the next post.
The address and network interface name are used for cross-node communication between vLLMs inside the Ray cluster we're going to setup.SETUP RAY CLUSTERAfter starting the container on each node, enter each container(for example,
docker exec -it head-node bash) to start the Ray process.- In the
head-nodecontainer: runray start --head --block - In the
worker-nodecontainer: runray start --block --address="HEAD_NODE_ADDRESS"
--head argument), take note of the address information that starts with To add another node to this Ray cluster.... This address is probably the one you should put as the HEAD_NODE_ADDRESS in your worker node command.Now when you run ray status inside your head node container, you should see the two node cluster in action.Example of a 2 node Ray cluster (using ray status)With all the steps completed, get inside the head node container and run your vLLM serving command..
- e.g.
vllm serve repo/model-name --tensor-parallel-size=8 --pipeline-parallel-size=2 --distributed-executor-backend=ray
Adjust the tensor parallel size and pipeline parallel size accordingly, but the pipeline parallel size should match the node count. Be sure to set the
distributed-executor-backend argument as ray to explicitly tell vLLM to use the Ray cluster, otherwise it would use mp(multiprocessing) by default which would not be able to do multi-node serving.If vLLM fails during startup and outputs logs related to insufficient GPU or memory, that's probably because vLLM failed to initialize the distributed backend using Ray. Our team has encountered several different types of issues related to this, but usually it comes down to one of two things- Is the ray cluster set up correctly?
- Can vLLM actually use the Ray cluster?
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-Instruct-2507",
"prompt": "The future of AI is ",
"max_tokens": 64
}'
{
"id":"cmpl-39d9a7dd43194475a3faf5859e8d9a5d",
"object":"text_completion", "created":1756781087,
"model":"Qwen/Qwen3-235B-A22B-Instruct-2507",
"choices":[
{
"index":0,
"text":"3D\nAI has been largely 2D up until now, focused on processing images, videos, and other flat data. But the real world is 3D, and AI needs to understand spatial relationships to reach its full potential. 3D AI will enable machines to interact with the physical world in more intelligent",
"logprobs":null,
"finish_reason":"length",
"stop_reason":null,
"prompt_logprobs":null
}
],
"usage":{
"prompt_tokens":6,
"total_tokens":70,
"completion_tokens":64,
"prompt_tokens_details":null
}
}LOOKING AHEADThis blog has outlined the simplest way to set up distributed vLLM inference in a multi-node environment. The setup demonstrates the fundamentals of how large models can be distributed across multiple nodes using proven technologies like Ray. In our next post, we'll take this setup a step further by exploring how InfiniBand (IB) can accelerate inference, and how tools like KubeRay can streamline the multi-node deployment process.